本页目录 · 7▾
· 1 分钟阅读
Claude Opus 4.8 上线当天,Anthropic 把模型竞争推向“工作流”
Claude Opus 4.8 的发布重点不只是跑分提升,而是 Anthropic 正在把模型能力、成本控制、代理工作流和用户信任放进同一个产品叙事里。
5 月 28 日,Anthropic 把 Opus 4.8 推到台前。The New Stack 的 Meredith Shubel 在报道里写 effort controls、dynamic workflows、cheaper fast mode 和 less deception;Linux.do 的讨论更像发布会门口的散场聊天:有人拿同一条 prompt 比截图,有人盯着中文里那些别扭词,有人说它“又能说人话了”,也有人嫌它慢、像翻译腔,甚至想退回 4.6。同一天里,报道谈更大规模的代理工作流,社区试中文、HTML 输出、限额变化和第一手手感。更重要的线索是,Anthropic 正在把 Claude 从“更强模型”推向“可调度的工程系统”。
两个现场:报道说工作流,用户试“说人话”
这两个现场不在同一张桌子上。The New Stack 写的是最新旗舰模型、同价升级、可调 effort、fast mode 变便宜;Linux.do 这边,用户把同一条 prompt 喂给 Opus 4.6 和 4.8,贴出两张长图,一张 1920×12694,一张 1920×14632。讨论焦点不是某个榜单,而是 HTML 写得像不像样、中文顺不顺、人读起来累不累。
“刚刚简单用了一下4.8,感觉 说人话 这方面,要比4.7强一些的,其他还没详细测试。”
— wonan, Linux.do
这句反馈有用,恰恰因为它没有装成评测。社区第一轮体感通常不是结论,而是温度计:中文自然度、错别字、语气、是否像 GPT、是否像机翻。这些很难由官方 benchmark 直接捕捉,却会决定团队会不会把一个模型放进真实工作流。Anthropic 讲“工作流”,用户先问“能不能正常说话”,听起来错位,其实是同一件事的两端。没有稳定表达,再漂亮的 agent 规划也会在落地时磨人。
Opus 4.8 不是一次单点升级,而是一次控制权重排
Opus 4.8 的定位很清楚:Anthropic 的新旗舰模型,价格与 Opus 4.7 持平,同时引入 effort controls。这个变化比“更强”具体得多,因为用户不只是选择模型,也开始选择模型愿意花多少力气。过去我们习惯在模型之间切换,像在菜单上点不同套餐;现在 Anthropic 把一部分调度权放到同一个模型内部,把油门和挡位从发动机舱拉到了驾驶席。
同价并不等于没有变化。真正变化在控制面:低 effort 更快,rate limit 消耗也更慢;高 effort 留给复杂推理、代码迁移和长任务。团队的调用账本会跟着改写。以前为了省钱,大家可能在小任务上降级到更便宜的模型;现在,同一个 Opus 4.8 里也有“轻一点跑”和“重一点跑”的区分。Anthropic 不是只把更大的模型扔出来,而是在提醒开发者:模型能力开始像算力资源一样,需要被调度。
漂亮数字要带着保留读
The New Stack 把几组数据放在了台面上:Opus 4.8 在 agentic coding 上是 69.2%,高于 Opus 4.7 的 64.3%;agentic compute use 是 83.4%,也压过文中列出的 GPT-5.5 78.7% 和 Gemini 3.1 Pro 76.2%。fast mode 的说法同样抓眼:速度是正常模式的 2.5 倍,成本相较此前模型便宜 3 倍。这些数字像新车发布时的赛道圈速,能说明厂商调校方向,也能制造第一波声量,但开回真实道路之后,堵车、弯道、载重和司机习惯都会改变体感。
“is now three times cheaper than it was for previous models.”
— The New Stack
保留项也要放在同一段里。The New Stack 的讨论基于发布日信息和 Anthropic 来源图表,没有给出独立真实项目里的长期验证;文中还提到,agentic terminal coding 上 Opus 4.8 相比 GPT-5.5 低 3.6%。再往下看,GPT-5.5 的 agentic coding 数字被印成 “58.65”,旁边其他值都有百分号。这种细节会提醒读者:发布日材料适合判断方向,不适合直接拿来做采购结论。跑分能告诉我们模型厂商想赢哪里,但不能替团队省掉试用、迁移和回滚成本。
Dynamic workflows 才是 Anthropic 想讲的新故事
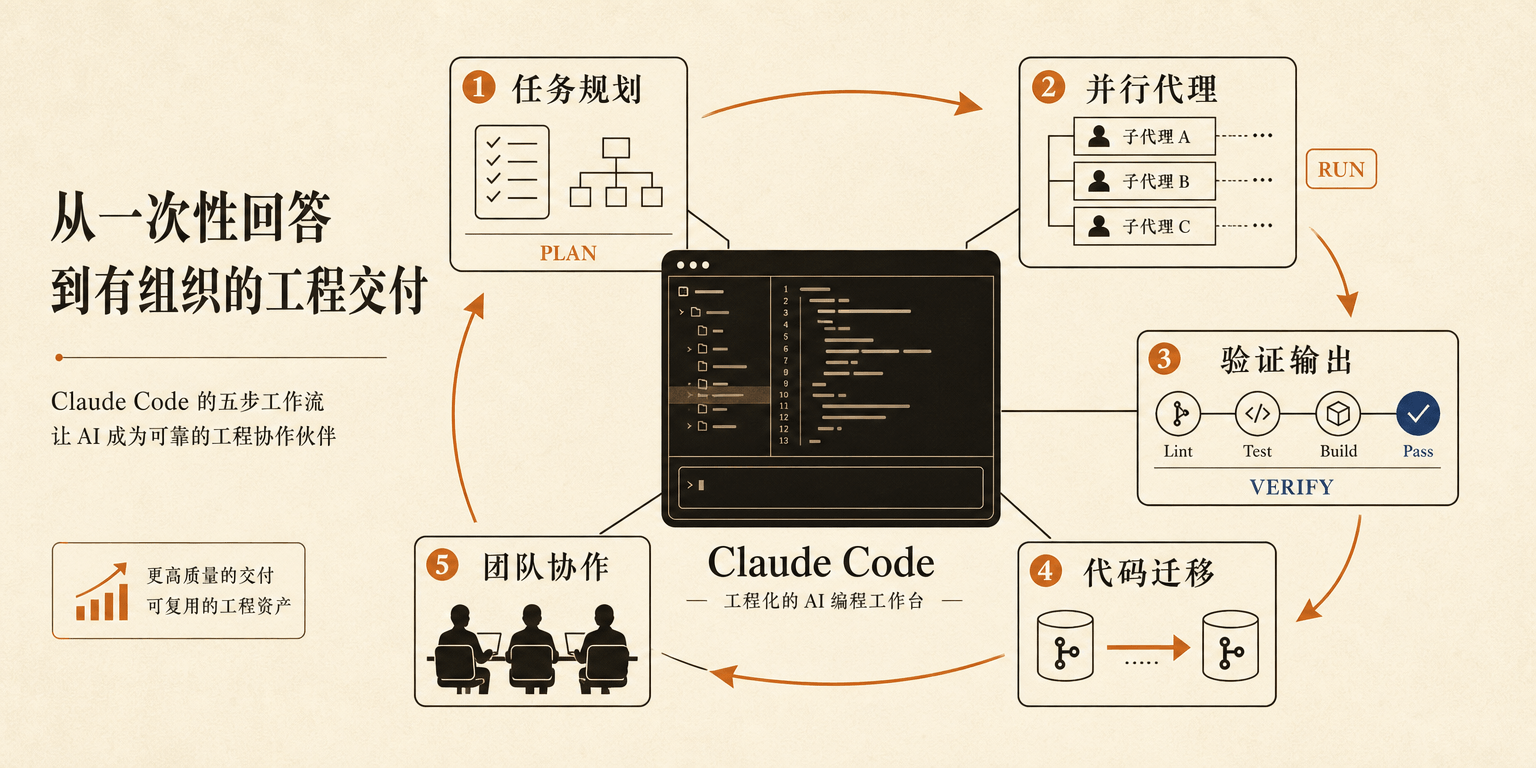
如果只看分数,Opus 4.8 很容易被写成又一轮模型竞赛。但 Anthropic 真正想讲的新故事,是 Claude Code 里的 dynamic workflows:它不只是回答一个问题,而是先规划任务,再并行调用 subagents,验证输出,最后处理代码库级迁移。叙事重心从“模型有多聪明”移到了“模型怎么组织工作”。主模型不再只是单线程吐答案,而是变成一个调度者。
“plan the work and then run hundreds of parallel subagents in a single session.”
— The New Stack
这部分才是 Opus 4.8 发布里更该被拆开看的地方。过去两年,AI coding 的竞争常被压缩成谁在 SWE-Bench 上高几分、谁补全更准、谁少犯低级错;现在 Claude Code 把问题推到团队层面:一个迁移任务能不能拆开并行跑,输出能不能系统性验证,失败后能不能回到中间状态继续修。真正的竞争对手也不只是另一个聊天模型,而是人类团队里那套已经运行多年的 issue 拆分、code review、CI 和发布流程。
社区反馈没有形成共识,这更接近真实使用
Linux.do 的几条讨论没有给出一致答案。有人说 4.8 比 4.7 更会说人话,有人觉得它少了一些黑话;也有人说像 GPT、像机翻,甚至不如 4.6。另一个帖子里,用户说 4.8 “靠谱那么点”,但慢,而且输出里冒出大量日语。这个分歧很正常。真实使用不是单一考卷,prompt、语言、任务类型、温度设置、上下文长度,都会把一个模型推向不同的侧面。
“除了全是日语,然后又慢,其他的感觉比4.7靠谱那么点”
— lian_lian, Linux.do
这类话比标准化评测粗糙,但它接近社区讨论里的真实噪声。一个用户在中文自然语言任务里感到进步,另一个用户在多语言输出里遇到失控,第三个人拿 HTML 页面看视觉结构,它们不是互相推翻,而是在提醒我们:模型发布不是一次性开关,而是很多小场景同时重新洗牌。社区没有形成共识,反而比一边倒的夸赞更有参考价值,因为它把发布材料里折叠掉的体验差异重新摊开了。
更快、更便宜、更诚实:Anthropic 同时在修三条线
Opus 4.8 的另一个层面,是 Anthropic 把成本、速度和安全放进同一套叙事里。低 effort 更快,rate limit 消耗更慢,fast mode 又把高频调用成本往下压;与此同时,The New Stack 写到 Anthropic 宣称 Opus 4.8 更支持用户自主与最佳利益,并减少欺骗和配合滥用。三条线放在一起看,意味着 Anthropic 不只在调模型输出,也在调使用边界:跑得快、花得少、出事少,缺一条都会影响团队是否长期采用。
“是因为推出4.8,还是因为happy Friday?”
— Papain233, Linux.do
这句关于周限重置的提问,应该按提问处理,不能写成确认事实。源帖本身就在问 4.8 发布和 “happy Friday” 哪个才是原因,候选材料里也没有 Anthropic 的确认。更稳妥的读法是,用户已经把模型能力、限额、fast mode 和额度体验连在一起看了。对 Anthropic 来说,这也是新问题:当模型成为日常工程工具,用户不会只问“聪不聪明”,还会问“今天能跑多少次”“慢不慢”“为什么昨天能用今天不行”。
接下来要看 Claude Code 会不会真的改变团队协作
接下来,真正该看的不是早期口碑会不会翻转,而是 dynamic workflows 能不能在真实代码库迁移里稳定工作。能规划任务是一回事,能在多分支、多依赖、测试不完整的旧代码里跑通,是另一回事;能开出成批 subagents 是一回事,能把它们的输出收束成可 review 的改动,又是另一回事。
“提示词都是同样的,”
— Ge0metry, Linux.do
这句朴素的控制变量,可能比很多早期判断都更有用。Opus 4.8 后面要观察几件事:dynamic workflows 是否真能把代码库级任务拆稳;fast mode 是否改变高频调用的成本结构;中文和多语言表达是否在后续使用中稳定下来;社区关于周限重置的猜测是否会有官方口径。发布材料能给方向,不能给定论。Claude 正在从一个会回答的模型,变成一个可以调度的工作系统;这件事还在演进,下一步要看它能不能扛住团队协作里那些不漂亮、但每天都会发生的任务。