本页目录 · 6▾
· 1 分钟阅读
75% 折扣转正:DeepSeek 用 V4-Pro 改写大模型调用成本
DeepSeek 将旗舰 V4-Pro 的 75% 折扣改为永久价格,使开发者调用成本维持在原来的四分之一;这场降价不只改变模型价格表,也会迫使 AI 应用公司重新计算默认功能、毛利和模型选择。
DeepSeek 把旗舰模型 V4-Pro 的 75% 折扣转正了。彭博社在 2026 年 5 月 23 日 报道,这个价格会停在原来的 1/4;DeepSeek 官网价格页也写明,V4-Pro 已经 “officially adjusted to 1/4 of the original price”。
这不是一次月底前冲量的短促销。原本写着 2026/05/31 15:59 UTC 到期的折扣,现在变成长期价格。对开发者来说,区别很实在:临时折扣只能用来跑样本,永久价格才会进预算表、产品档位和毛利模型。
折扣转正,DeepSeek 不等月底就改牌桌
彭博这篇报道的标题很直接:“DeepSeek To Make Permanent 75% Discount on Flagship AI Model.” 信息只有一刀:DeepSeek 会把 V4-Pro 的陡峭折扣永久化,让开发者价格停在原来的 1/4。
“at a quarter of their original level”
— Bloomberg
这句话能确认的,是 V4-Pro 的开发者价格从限时折扣价变成了长期价。至于下游应用会不会扩大默认调用、重做套餐、把更多 agent 功能打开,现有报道还没有给出数据。能先写进表格的,是 V4-Pro 的基准价格已经换了。
模型行业里,临时折扣和永久价格不是同一件事。前者适合压测、试水、做 demo;后者才会进入一家公司对功能成本、用户消耗和付费毛利的长期测算。DeepSeek 这次改的不是宣传口径,而是开发者每天会看到的那张价格表。
V4-Pro 现在到底有多便宜
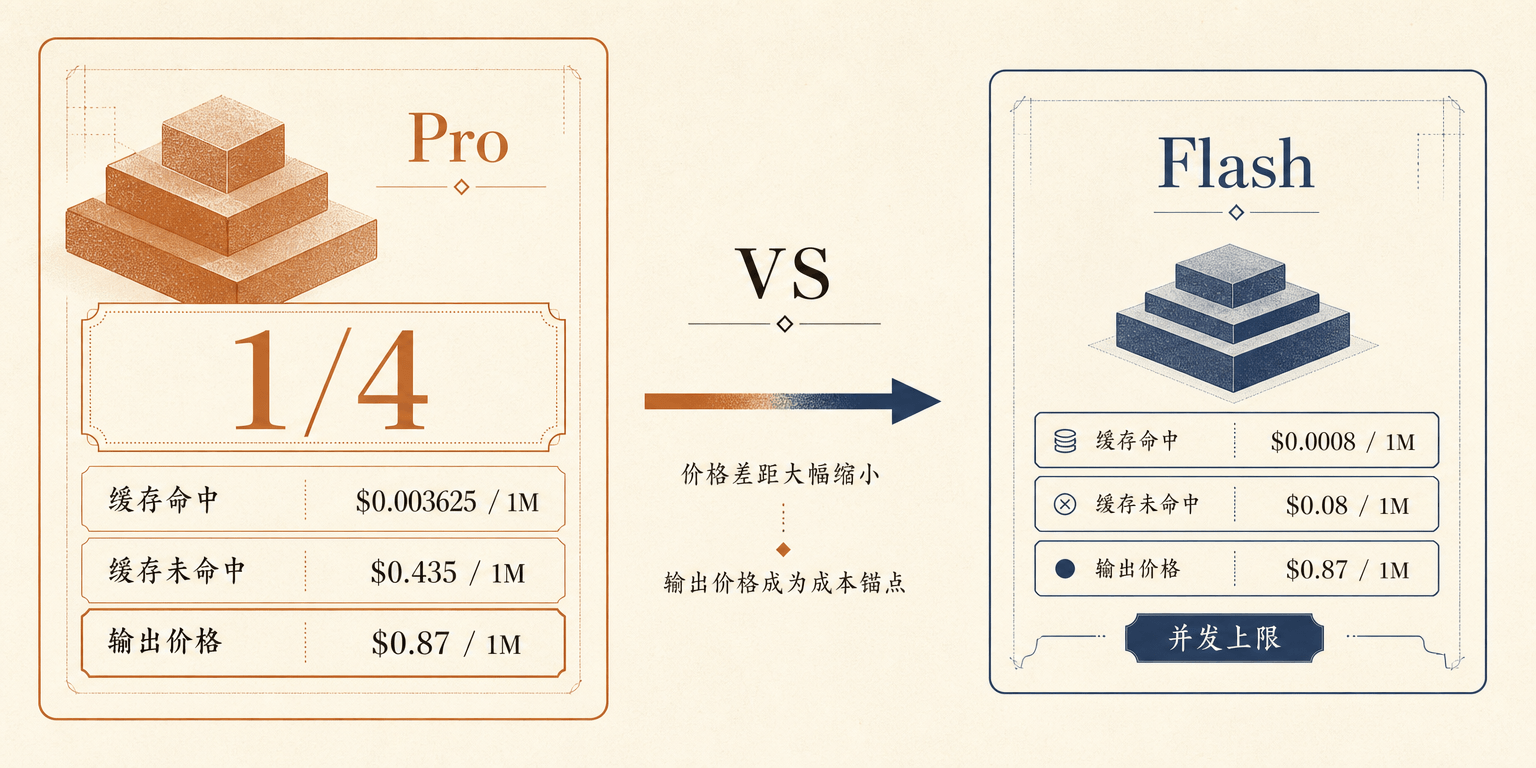
DeepSeek 官网价格页给出的 V4-Pro 新价,是这次新闻里最硬的部分。deepseek-v4-pro 的输入 cache hit 价格为 $0.003625 / 1M tokens,原价是 $0.0145;输入 cache miss 价格为 $0.435 / 1M tokens,原价是 $1.74;输出价格降到 $0.87 / 1M tokens,原价是 $3.48。
三项都落在原价的四分之一,和彭博报道里的永久 75% 折扣对应起来。如果一个产品的成本主要来自输出 token,$0.87 / 1M tokens 就会变成关键参数。生成、改写、解释、总结、代码补全和多轮 agent 调用,都会把输出 token 写进账单。
同一张价格页还列出了 deepseek-v4-flash:输入 cache hit 为 $0.0028 / 1M tokens,cache miss 为 $0.14 / 1M tokens,输出为 $0.28 / 1M tokens。两款模型都给出 1M context length 和 384K max output,但并发限制不同,V4-Pro 是 500,V4-Flash 是 2500。
便宜的不是边角料,而是旗舰 Pro
这次降价有反差,是因为被永久降价的不是边角料模型,而是 DeepSeek 当前价格页里的旗舰 Pro。官网现在列出的两个当前模型是 deepseek-v4-flash 和 deepseek-v4-pro;两者都支持 non-thinking 和 thinking 模式,且 thinking mode 被列为默认。
接口形态也没有被藏在另一个入口里。两款模型都提供 OpenAI-format base URL https://api.deepseek.com,以及 Anthropic-format base URL https://api.deepseek.com/anthropic。换句话说,DeepSeek 把低价放在当前模型和主接口上,而不是只给一个过渡版本降价。
Reuters 经由 MarketScreener 给出的背景是,V4-Pro 在发布时最高曾比 Flash 贵 12 倍。这个比例能帮人理解 Pro/Flash 的价格梯度:永久降价之后,Flash 仍然更便宜、并发上限也更高;Pro 则把自己的价格固定在原来的 1/4。
对开发者来说,选模型不是“最好”和“最省”的二选一。cache hit、cache miss、输出 token、上下文长度和并发上限都要一起进成本模型。V4-Pro 的新价,等于把“旗舰能力能不能默认用”这个问题重新放回桌面。
月底倒计时被改成长期价格
整件事最有戏剧性的细节,不在标题里,而在价格页原本的倒计时里:促销截止时间写着 2026/05/31 15:59 UTC。有截止时间的价格,很难直接写进长期毛利模型;团队可以趁促销跑评测、压测功能、算一批样本,却不能假设下个月还按这个价结账。
“set to expire at the end of May”
— Bloomberg
现在 DeepSeek 把 V4-Pro 的折扣永久化,等于把一个限时机会改成长期参数。客服产品、IDE、搜索和内容生成产品如果使用 V4-Pro,都可以重新计算每次会话、每次补全、每次长上下文分析的成本。
最直接被改变的,是价格假设本身。过去月底到期的模型价格更像一次窗口期;永久价格改变的是产品决策的时间尺度。一个团队要不要把更多 token 消耗写进默认体验、付费档或后台 agent 链路,现在可以用新的长期价格重算一遍。
Ascend 950 的影子,和没被确认的因果
Reuters 补充了供应链背景:市场此前预期,V4-Pro 可能要等华为 Ascend 950 supernodes 在 2026 年下半年 大量推出后才会变便宜。这个背景很关键,因为模型定价不只取决于商业策略,也会受算力供给、推理效率和高端芯片约束影响。
Reuters 同时提到,此前的价格区间从每百万 tokens 0.1 到 24 元人民币,降至 0.025 到 6 元人民币,美元等价大约是每百万 tokens $0.0035 到 $0.83。这组数字把降价幅度放进了更大的推理成本背景里。
但这里不能把故事写过头。Reuters 明确说,DeepSeek 没有披露永久降价是否来自华为 Ascend 950 芯片供应增加。它提供的是一个行业理解框架:如果高端算力供给紧,旗舰模型价格很难长期大幅下探;如果推理资源约束缓解,价格才可能从短促销变成长期承诺。
眼下能确认的事实只有两个:DeepSeek 把 V4-Pro 的 75% 折扣永久化;外部报道提到,市场曾把更便宜的 V4-Pro 和 2026 年下半年 的 Ascend 950 supernodes 放在同一条预期线上。因果关系还差一块官方披露。
价格战下一步,是重算应用毛利
这次降价先改变的,是 V4-Pro 的成本输入项。过去下游公司会问“哪家模型能力更强”,现在还要把另一个问题放进测算里:某个功能默认打开以后,每个用户触发多少次、每次消耗多少 token,最后怎样影响毛利。
模型便宜一点,可能只是账单好看;旗舰模型永久便宜到原来的 1/4,会改变这类测算的起点。只要开发者拿 V4-Pro 的 $0.435 / 1M tokens cache miss 和 $0.87 / 1M tokens 输出价做横向比较,其他旗舰模型的价格就多了一个清楚参照。
接下来要看的,不只是 DeepSeek 会不会再发一条降价公告,而是 Pro 和 Flash 的价差会不会继续变化,其他模型厂商会不会跟进旗舰价位。对下游公司来说,便宜 API 不是新闻的终点;当一个旗舰模型把低价固定下来,更多 AI 功能能不能进入默认体验,要看各家公司自己的成本、质量和产品收益计算。