本页目录 · 7▾
· 1 分钟阅读
没有标准答案的 Agent 开发:企业场景里的可控性之争
一场 LINUX DO 上关于 Agent 开发框架的讨论显示,企业 AI 工具建设正在 LangGraph、轻量 SDK、自研基座与 HITL 流程之间寻找平衡;开发者的共识不是押注某个万能框架,而是在可控性、自动化和工程成本之间重新划线。
2026 年 5 月 20 日 15:20,LINUX DO 用户 stk 在“开发调优”分类下发起“大家现在做agent都是用什么开发框架”的讨论,问题来自一个具体的企业现场:怎样用 AI 工具提高工作效率。首帖获得 22 Likes,页面抓取显示 Page 1 展示 1-20 号帖子,Page 2 展示 21-40 号帖子;候选摘要仍停留在“6 个帖子 - 5 位参与者”,与抓取页面状态并不一致。
围绕 LangGraph、AWS Strands、Claude Agent SDK、Agno、OpenAI Agent SDK 与自研方案,开发者们没有给出一个万能答案。讨论最后指向的是同一个问题:企业要的往往不是完全自动化的 Agent,而是可控、可介入、能被放进现有流程里的提效系统。
一个企业 AI 工具问题,引出 Agent 框架选择的现实分歧
stk 的首帖并不是在问“哪个框架最先进”,而是在问企业内部工具到底怎样落地。按照他的描述,当前场景更像是用 LangGraph 搭一个 workflow,部分节点可以做成小 agent,但整体流程必须可控,工具输入和输出也要符合预期。这一点让讨论从框架名称转向工程约束:业务需要稳定流程、明确的工具输入输出和适当人工介入时,Agent 的自主性就不再是唯一目标。
这个问题之所以引发回应,是因为它踩中了很多企业 AI 工具的共同矛盾。一边是通用 agent 与专用 agent 的取舍,另一边是企业内部流程对可控性、权限校验和 HITL 的要求。stk 还提到,当前需求更多是“工具属性”,不要求彻底 automated,而且需要适当 HITL。换句话说,这场讨论真正比较的不是 LangGraph 与某个 SDK 的胜负,而是企业愿意把多少控制权交给模型。
workflow 为什么重新成为企业默认选项
在讨论中,workflow 重新成为高频词,是因为多位发帖者把它和安全性、模型能力、可控性联系在一起。gaopan 的判断代表了其中一条主线:如果安全性要求高,或者模型能力还不足以稳定完成任务,企业通常会用 workflow 来支撑;企业目标是提效,不一定需要 LLM。这里的意思很直接,AI 工具不是为了展示模型能做多少自由动作,而是为了让一个业务过程更快、更稳。
wusimpl 的观点把这个判断进一步工程化:不同 Agent 范式适用于不同业务场景,建议先从简单方案开始,需求不满足时再提高复杂度。流程能用普通代码完成,就不必强行让 LLM 参与;需要模型判断的节点,可以设计成局部 agent;需要人确认的环节,则通过 HITL 留出介入点。这样的设计不追求“全自动”叙事,却更贴近真实组织里的可控性、权限校验和稳定性要求。
“没有标准答案”:开发者把框架选择拆成场景选择
NXDOMAIN 在回复中把这场讨论的基调说得很清楚:相关板块还很新,框架选择不能脱离业务边界。需要可控性的场景,他认为 LangGraph 是稳妥选择;但他也提到,自己近期做的是深度绑定 AWS 生态的系统,AWS Strands 能连接多种 AWS 服务。这里的差别不是谁更先进,而是谁更贴近部署环境、云生态和服务连接需求。
这板块还很新,的确没有标准答案
需要可控性的话,目前 LangGraph 基本错不了
wusimpl 的一句话则把“框架之争”拆成了“范式选择”。不同业务里,Agent 可能是 workflow 中的一个节点,也可能是能调用多工具的执行器,还可能只是某个搜索、摘要或校验流程里的局部能力。企业开发者真正要回答的是:流程是否稳定,权限校验是否清晰,工具输入输出是否符合预期,人能否在关键节点介入。
没有好坏之分,不同的Agent范式适用于不同的业务场景
从 LangGraph 到手搓基座:框架清单背后是控制权清单
当讨论进入具体工具,分歧变得更清楚。iuikj 的做法是用 LangGraph 编排垂直业务,在节点内使用 deepagent 和 create agent,或者把它们作为 subgraph 接入。这一做法把 LangGraph 放在编排层,把更自由的 agent 能力放在节点或 subgraph 中。
另一边,cqrect 选择“手搓”agent,通过统一工具调用层协议来做外部流程和权限校验;echoVic 提到优先选择 claude-agent-sdk,轻量场景用 pi,个人项目用 @blade-ai/agent-sdk;yuanpi 推荐 Agno、OpenAI Agent SDK,同时认为 LangGraph 对部分场景“太重”。这些选择看似是一张工具清单,实际对应的是一张控制权清单:要不要深度绑定某个云生态,要不要使用框架编排流程,要不要自己维护工具调用协议和权限校验,要不要在轻量场景里降低工程复杂度。每一种答案都在交换开发成本、可控性和长期维护负担。
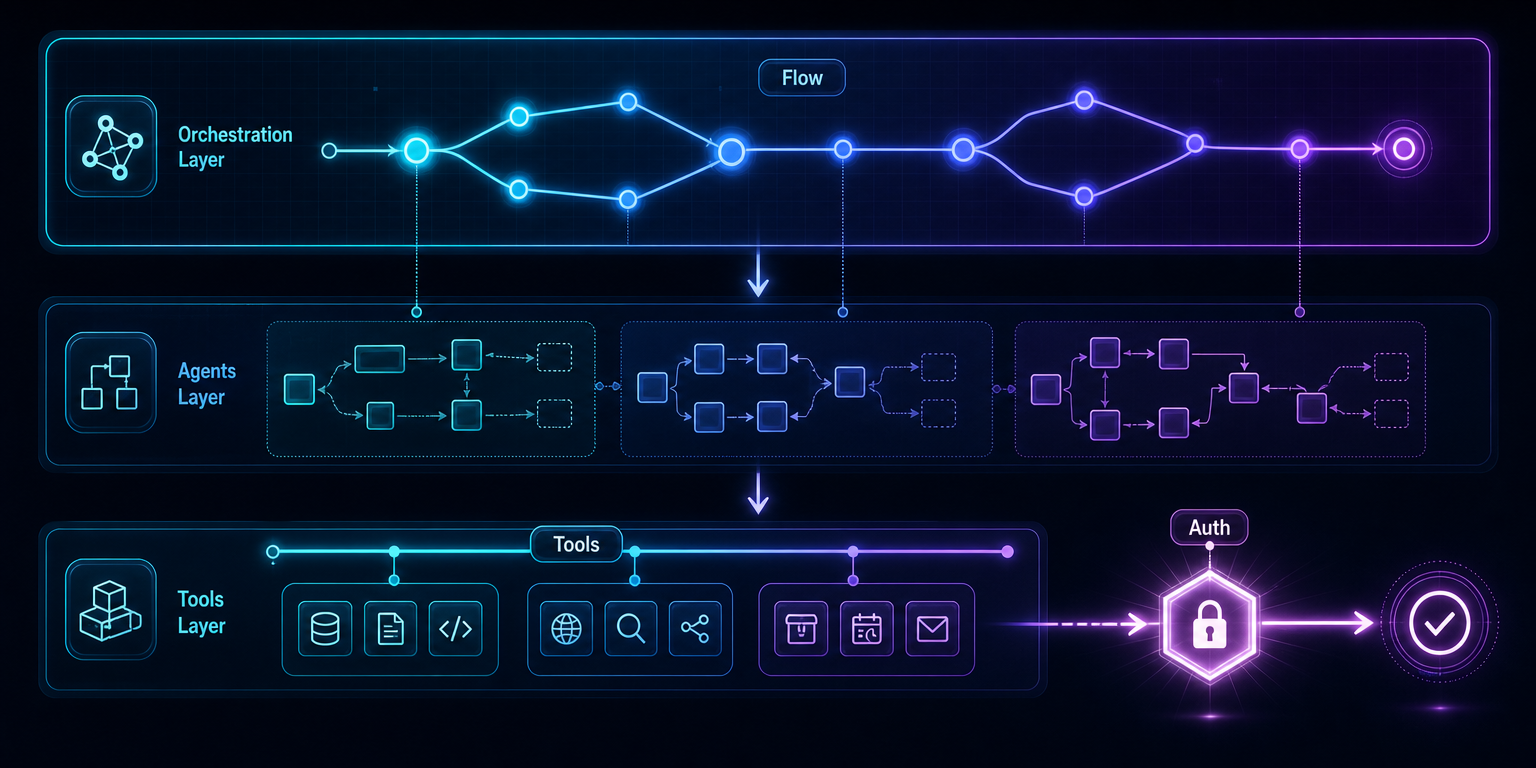
论文检索 Agent 的例子:自由度被装进一套检查流程
Wep-56 给出的论文检索/陪读 agent,是整场讨论里最能把抽象争论落地的例子。这个流程包括意图解析、Semantic Scholar / arXiv API 检索、本地向量库 + BM25 混合检索、去重排序、HITL、批量摘要和综合节点。一个看似“智能陪读”的任务,并没有被描述成模型拿到问题后自由浏览、自由判断、自由总结,而是被拆成一串可以检查的环节:先理解意图,再从学术 API 和本地知识库取证,再排序去重,再让人确认,再批量摘要,最后进入综合节点。
这个细节重要,因为它揭示了生产级 Agent 的另一面。所谓智能,并不是让模型一路跑到底,而是把模型放进一条有证据、有停顿、有人工确认的管道。检索环节可以检查来源,排序环节可以检查相关性,HITL 可以拦住方向错误,摘要和综合节点则承担语言生成与信息组织。企业真正购买的不是 Agent 的自由,而是受控自由带来的效率。
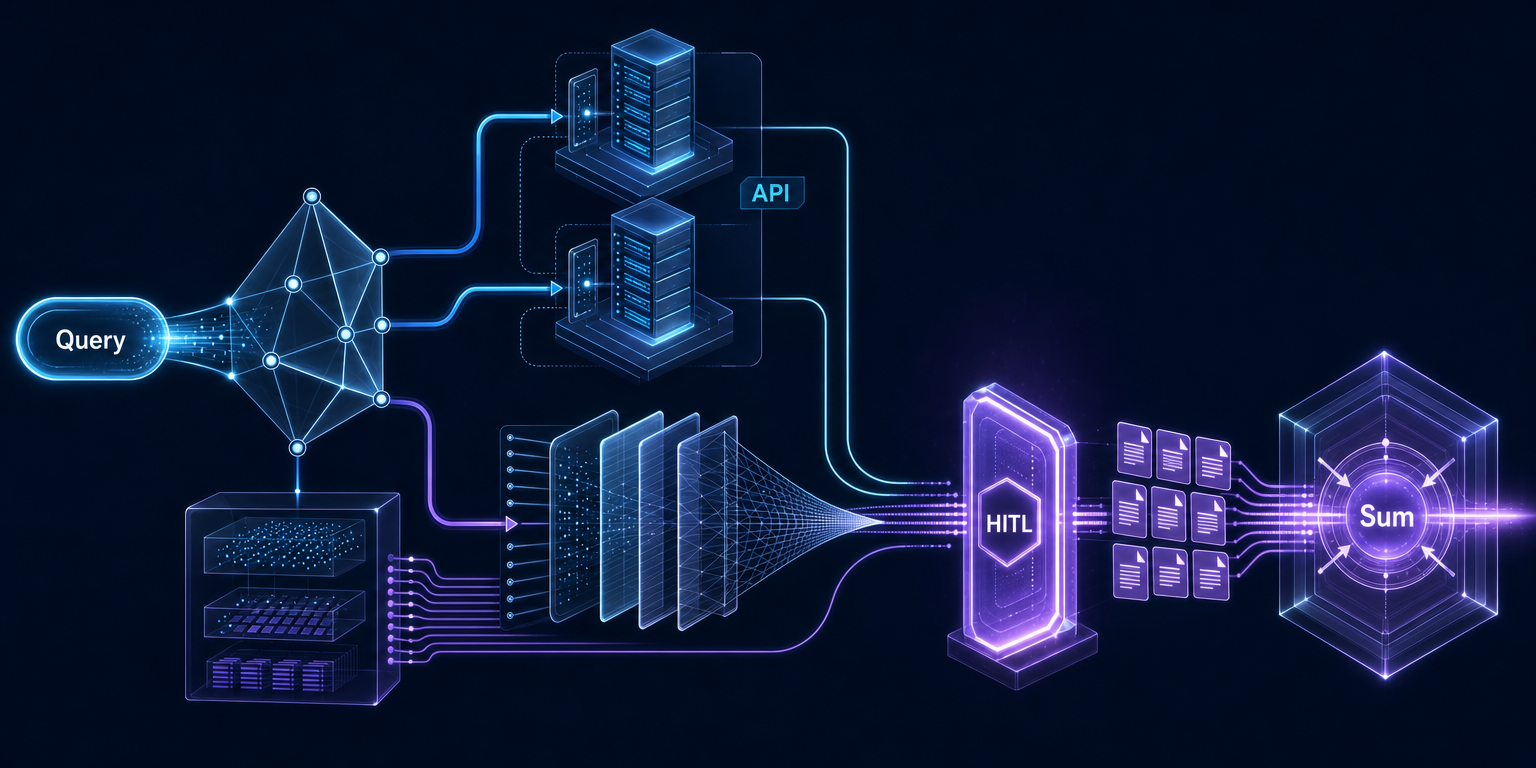
通用 Agent 的诱惑,与专用 Agent 的现实成本
第二页中,imdoge 提出一种折中路径:结合 workflow 固定性与 agent 自由度,采用高层控制、低层 agent 自由,并使用 harness、gate、policy、protocol 等机制。这个思路把“workflow 意味着流程方向更固定”的限制转化为结构优势:上层流程负责方向和边界,下层 agent 负责局部探索和执行。它承认模型需要一定自由度,也承认企业流程不能完全交给自由度。
stk 对 Claude Code 式通用实现的怀疑,则把问题拉回成本。很多企业需求更像专用 agent,而不是通用 agent;直接借用 Claude Code 的实现可能需要大量改动,性价比不高。这里还涉及一层风险边界:论坛用户提到 Claude Code 泄露源码相关法律风险,但没有附带法律文件或官方声明,因此只能作为讨论中的顾虑,不能写成确定结论。真正确定的是,通用 Agent 的工程吸引力很强,但企业内部落地常常要为专用流程、专用权限和专用数据源重新改造。
余响:Agent 工程化仍在寻找边界
这场 LINUX DO 讨论不是官方基准,也不是框架评测;“LangGraph 太重”“claude-agent-sdk 优先选择”“Agno、OpenAI Agent SDK 推荐”“手搓 agent”等判断都来自个人经验,缺少可复现实验数据。它更像一张生产现场的截面:企业 AI 工具正在可控 workflow、轻量 SDK、自研基座与 HITL 之间重新划线。
接下来值得观察的是,团队会不会形成更稳定的评估指标,HITL 是否成为生产级 Agent 的默认组件,以及框架生态会不会继续向轻量化和协议化收敛。眼下更现实的结论是,Agent 开发没有单一标准答案,只有围绕业务边界、风险等级和工程成本不断缩小的选择范围。